

「ログイン中のはずが突然401エラーで弾かれる」等、開発者を悩ませるのが「401 Unauthorized(未認証)」です。
【端的な結論】401エラーとは?
一言で言えば、「あなたが誰だか証明できない(未認証)」ため、サーバーからアクセスを拒否された状態を示すHTTPステータスコードです。
- 主な原因: ID・パスワードの入力ミス、ログイン期限(セッションやトークン)の切れ、認証設定の不備。
- 解決策: ページをリロードして再度ログインし直すか、開発者側でトークンの自動更新(リフレッシュ)処理を実装する。
本記事では、401と403の決定的な違いから、JWTなどモダンなAPI認証のアーキテクチャ、Googlebotへの有料記事の正しいペイウォール制御まで徹底解説します。
Google公式ガイドラインおよびRFC(インターネット技術標準)の見解
「401 (Unauthorized) ステータスコードは、リクエストが有効な認証資格情報(authentication credentials)を欠いているため、ターゲットリソースに適用されていないことを示します。サーバーはレスポンスの中に、クライアントがどのように認証すべきかを示す WWW-Authenticate ヘッダーフィールドを含めなければなりません。」
(引用元:RFC 7235 – HTTP/1.1: Authentication Section 3.1)

401エラーとは?「403」との決定的な違い
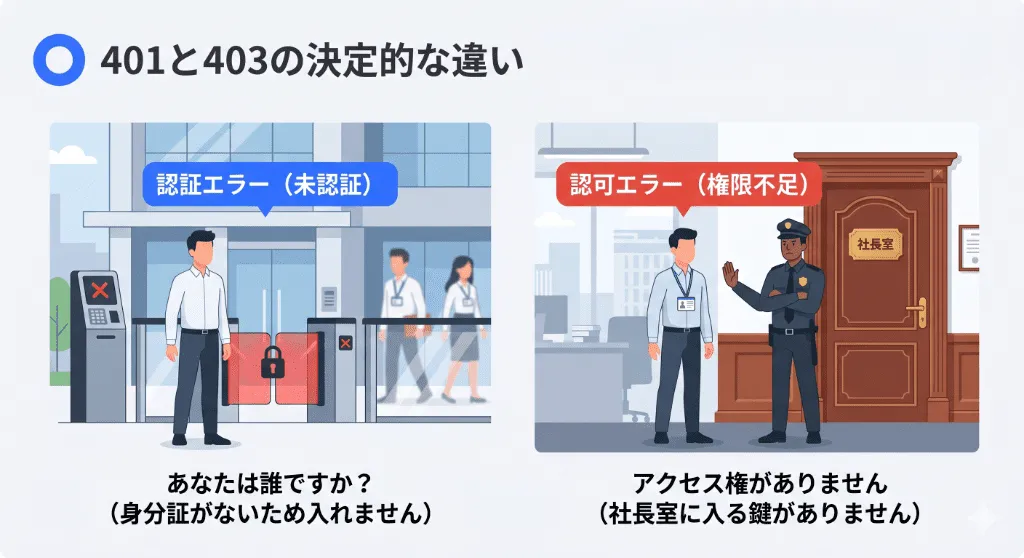
401エラーを正しくデバッグするためには、まず「401とは何か」、そして混同されやすい「403」との違いである「認証」と「認可」の概念を理解する必要があります。
401 Unauthorized =「未認証(あなたは誰ですか?)」
「401エラーを端的に言うと、「あなたが誰だか証明されていない(未認証)ため、アクセスを拒否された状態」です。
直訳の「権限がない」ではなく、技術的な意味は「未認証」です。ログインID/パスワードの入力ミスや、セッション・トークンの期限切れによって「身分証を持っていない」と判定された場合に発生します。
403 Forbidden =「権限不足(アクセス権はありますか?)」
一方の403エラーは、「あなたが誰であるかは分かっているが、そのページを見る権限(認可)がない状態」です。
例えば、「一般ユーザー」として正常にログインした人が、「管理者専用ページ」にアクセスしようとした場合、システムは「社員証は持っているが、社長室に入る鍵はない」として403エラーを返します。
| コード | エラー名 | 技術的解釈(何が起きているか) | 例え話 |
| 401 | Unauthorized 【未認証】 | 認証情報(トークンやCookie)が存在しない、または無効(期限切れ・署名エラー)である。 | 「身分証(社員証)を持っていないので、会社のビルに入れません」 |
| 403 | Forbidden 【権限不足】 | 認証情報(身元)は正しく認識されているが、要求されたリソースに対するアクセス権が付与されていない。 | 「社員証は持っているのでビルには入れたが、社長室に入る権限はありません」 |
一般ユーザー環境で発生する401エラーの主要な原因と解決策
一般のユーザーが企業のWebサービスや会員サイトを利用中に401エラーに遭遇した場合、原因のほとんどは「認証セッションの喪失」です。
セッションのタイムアウト(期限切れ)
Webサイトにログインした後、タブを開きっぱなしにして数時間放置し、再び操作をしようとしてボタンを押した瞬間に401エラー(またはログイン画面への強制リダイレクト)が発生するケースです。
サーバーは、セキュリティやメモリ節約のため、セッション(ログイン状態の維持)に有効期限を設けています。期限が切れた状態でリクエストを送ると、サーバーは401を返します。
- 解決策: ユーザー側は「ページをリロードして再度ログインし直す」しかありません。開発者側は、Ajax通信のレスポンス(401)をフロントエンドでキャッチし、「セッションが切れました。再度ログインしてください」というポップアップを出してログイン画面へ優雅にリダイレクト(UXの保護)させる実装が必須です。
Cookieの削除やプライバシー拡張機能の干渉
iPhoneのSafariで「サイト越えトラッキングを防ぐ(ITP)」が強力に作用している場合や、PCブラウザで広告ブロッカーを使用している場合、ログイン状態を維持するための必須のCookieまでがサードパーティCookieと誤認されてブロックされることがあります。
- 解決策: シークレットモードでの動作確認、ブラウザの拡張機能の一時的な無効化を行い、正常にログインできるかを切り分けます。
開発者・インフラエンジニア向け:API連携における401エラーのデバッグ
BtoBのシステム開発やマイクロサービスアーキテクチャにおいて、APIエンドポイントから返される高度な401エラーのメカニズムを解説します。
JWT(JSON Web Token)の署名エラーと期限切れ
モダンなSPAやスマホアプリの通信において、最も標準的な認証方式が「Bearerトークン(JWT)」です。クライアントは、HTTPリクエストのヘッダーに以下のようにトークンをセットして送信します。
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...バックエンドサーバーがこのJWTを受け取って検証する際、以下のいずれかに該当すると401を返却します。
| エラーの原因 | 具体的な状態と詳細 |
| 署名(Signature)の不一致 | 秘密鍵が環境間で異なる場合や、攻撃者が内容を改ざんした場合、署名検証関数がエラーを吐きます。 |
| 有効期限の超過 | JWT内の exp に記載された有効期限を1秒でも過ぎて送信されたトークンは機械的に拒絶されます。 |
| ヘッダーのフォーマットミス | Bearer 文字列の後に半角スペースが欠落しているなど、初歩的な実装ミスによるものです。 |
OAuth 2.0 / OIDCにおけるアクセストークンのリフレッシュ失敗
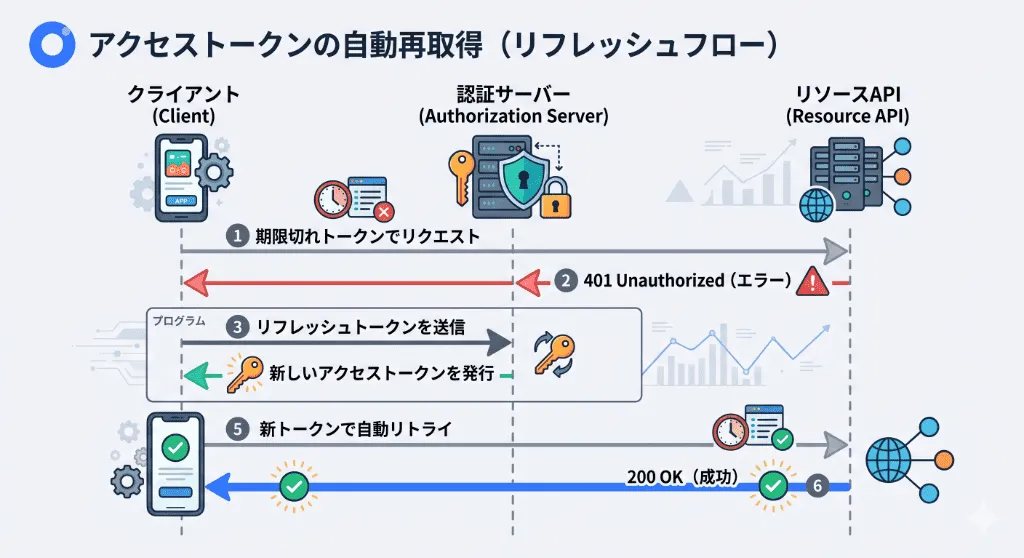
外部のSaaSと連携する際、OAuth 2.0を利用します。アクセストークン(Access Token)の寿命は非常に短く設定されており、期限切れのトークンでAPIを叩くと401エラーが返ります。
- アーキテクチャの解決策: 401エラーを受け取ったプログラムは、そこでエラー終了してはいけません。事前に受け取っている「リフレッシュトークン(Refresh Token)」を用いて新しいアクセストークンを再取得し、先ほど401で弾かれたAPIリクエストを「自動的に再送(リトライ)」するロジック(AxiosのInterceptorsなど)を実装しなければなりません。
NginxのBasic認証(auth_basic)の設定不備
ステージング環境や社内ツールを保護するために、NginxやApacheで「Basic認証」をかけるケースがあります。
# NginxのBasic認証設定例
location /admin/ {
auth_basic "Restricted Area";
auth_basic_user_file /etc/nginx/.htpasswd;
}
正しいID・パスワードを入力しても401エラーがループし続ける場合、原因は「.htpasswd ファイル内のパスワードのハッシュ化アルゴリズム」にあります。必ず htpasswd -B(bcryptアルゴリズム)など、モダンなハッシュ関数を指定してパスワードファイルを再生成してください。
CORS(クロスオリジン)とプリフライトリクエストの罠
フロントエンドとバックエンドのドメインが異なる場合、ブラウザは本番リクエストの前に「OPTIONSメソッド(プリフライトリクエスト)」を送信します。
ここで、バックエンド側で「すべてのエンドポイントはJWT認証(401チェック)を通らなければならない」というグローバルなミドルウェアを設定していると悲劇が起きます。OPTIONSリクエストには Authorization ヘッダーが付与されないため、バックエンドが401を突き返し、結果として「CORSエラー」が発生します。
- 解決策: バックエンドの認証ミドルウェアは、「OPTIONSメソッドのリクエストは認証チェックをスキップし、無条件で通す」ように除外設定を記述しなければなりません。
セキュリティアーキテクチャの深層:Stateful vs Stateless
401エラーの根本的な設計を理解するためには、Webアプリケーションにおける「状態管理(State Management)」の2大巨頭のアーキテクチャの違いを把握する必要があります。
Stateful(Cookie / セッション)アーキテクチャとCSRFの罠
サーバー側にセッションデータを保存し、クライアントに「Session ID」だけをCookieに乗せて渡すアーキテクチャです。
Cookieはリクエスト時に「自動的に送信される」性質があり、これを利用した攻撃がCSRFです。CSRFトークンが有効期限切れになった状態でPOST送信を行うと、CSRF防御機構が作動してリクエストを弾き、401(または403/419)を返却します。「ログインしているはずなのに更新すると401になる」現象の大半はこれです。
Stateless(JWT)アーキテクチャとXSSによるトークン奪取
サーバー側に状態を持たない「Stateless」なアーキテクチャです。
JWTをブラウザの localStorage に保存すると、XSS(クロスサイト・スクリプティング)の脆弱性に対して無防備になります。ベストプラクティスは、JWTを HttpOnly 属性と Secure 属性を付与したCookie に保存することです。ただし、Cookieに保存した時点で再びCSRFの脅威に晒されるため、「SameSite属性」を適切に設定して防御線を構築する必要があります。
マイクロサービスにおける「Auth Gateway」パターン
現代のインフラ設計では、すべての外部からの通信を最前線の「API Gateway」で受け止めます。
このGateway層に認証専用ロジックを集約し、JWTの有効期限や署名を一括で検証します。トークンが無効であれば、後ろのマイクロサービスを起動させることなくGatewayが即座に401を返します。これにより、システム全体のパフォーマンスとセキュリティが劇的に向上します。
401エラーとSEO:ペイウォールの正しい実装方法
Webメディアにおいて「ここから先は有料会員限定です」というペイウォールを実装する際、未ログインユーザーに対してHTTPステータスコード「401」を返してしまうと、SEO上極めて深刻な問題を引き起こします。
なぜGooglebotに401を返してはいけないのか
Googlebotは未ログインのユーザーと同じ扱いです。記事のURLにGooglebotがアクセスした際、サーバーが401を返してしまうと、Googlebotは「クロールする権限がない」と判断し、即座にインデックスから除外(検索結果から消去)してしまいます。
Googleが推奨するペイウォールの正しいSEO実装
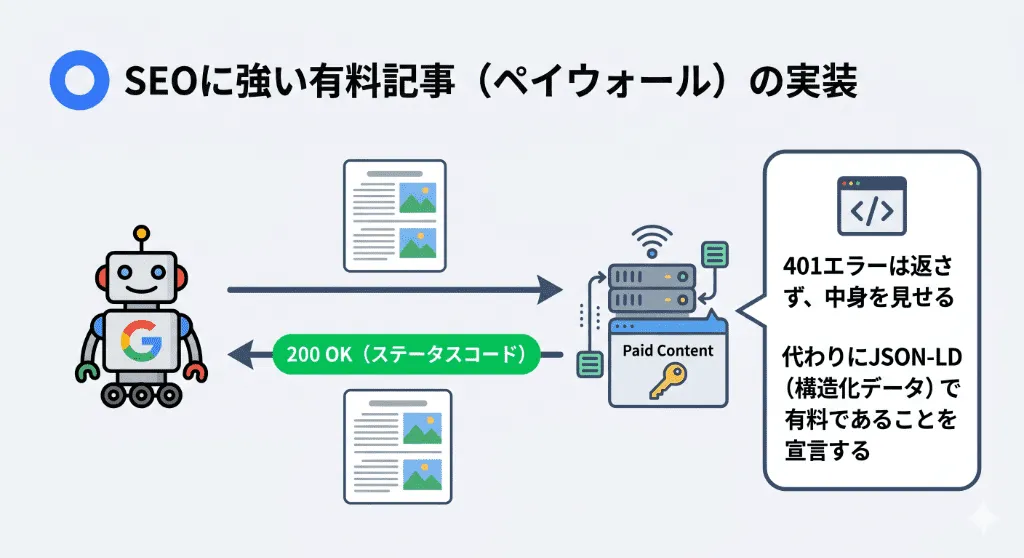
検索結果には記事をヒットさせたいが、中身は有料会員にだけ見せたい場合、HTTPステータスコードは必ず「200 OK」を返さなければなりません(401や403は厳禁です)。
その上で、Googleが「クローキング(検索エンジンにだけ中身を見せ、ユーザーには隠すスパム行為)」と判定するのを防ぐため、HTMLの <head> 内にJSON-LD形式の構造化データ(CreativeWork の isAccessibleForFree プロパティ)を記述し、Googleに対して明示的に「この記事の一部はペイウォールで保護されています」と宣言します。
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"headline": "画期的なAIツールの活用法",
"isAccessibleForFree": "False",
"hasPart":
{
"@type": "WebPageElement",
"isAccessibleForFree": "False",
"cssSelector" : ".paywall-content"
}
}
</script>
このように、有料部分をCSSクラス(例:.paywall-content)で囲み、構造化データとリンクさせることで、Googleは記事全体の内容を正しくインデックスしつつ、それが有料記事であることを理解してくれます。
よくある質問(FAQ)と高度なインフラ的疑問
Q1. 401エラーと404 Not Foundの違いは何ですか?
「認証」の有無と「存在」の有無の違いです。
401エラーは、対象のURLはサーバー上に「存在」していますが、「誰だか証明されていない」ため中身を見せてくれない状態です。一方404エラーは、そのURLにデータが「存在しない」ことを示します。
Q2. セキュリティのために、あえて401ではなく404を返すのはアリですか?
はい、高度なセキュリティ設計においてよく用いられる手法です。
管理画面のURLに攻撃者がアクセスした際、正直に401を返すと「ここに管理画面が実在する」というヒントを与えてしまいます。意図的に404を返し「そもそも存在しない」と嘘をつくことで、内部構造を秘匿する防御テクニックが存在します。
Q3. アプリの通信で「トークン期限切れ」のエラーコードは何番を返すのが正解ですか?
原則として「401 Unauthorized」を返します。
ただし、クライアント側が理由を区別できるよう、ステータスコードは401にした上で、レスポンスのJSONボディの中に独自のサブエラーコードを含めるのがベストプラクティスです。
{"status": 401, "error": "token_expired", "message": "Access token has expired."}
【専門家向け技術仕様】セキュアなクロールバイパスと高度なインフラ設計
ステートレスなJWT認証アーキテクチャにおける401エラーの自動復旧プロセス
「401 Unauthorized」が発生する最も一般的なケースは、アクセストークンの有効期限切れです。
シームレスなUXを提供するためには、フロントエンドにおいてAPIから401レスポンスを受け取った瞬間、バックグラウンドで「リフレッシュトークン」を送信し、新しいアクセストークンを非同期で再取得・再試行する「サイレントリフレッシュ(Silent Refresh)」のパイプラインを実装する必要があります。
Verified Googlebotに対するセキュアな認証バイパス設計
会員限定コンテンツをGooglebotにインデックスさせたい場合、ユーザーエージェント文字列だけで判定すると、容易に偽装され不正アクセスを許してしまいます。
これを防ぐため、NginxやAWS WAFのレベルでリクエスト元のIPアドレスに対して「Reverse DNS Lookup(逆引きDNS参照)」を実行し、そのIPが本当に googlebot.com に属しているか検証する「Verified Googlebot」ロジックをインフラレイヤーに組み込みます。この厳密な検証を通過した正規のクローラーに対してのみ、認証チェック(401)をスキップさせます。
Envoy ProxyとgRPC連携による高度な認証オフロード
Cloud Nativeなマイクロサービス環境では、「Envoy Proxy」などのサービスメッシュプロキシを配置し、gRPCベースの外部認証サービスと連携させます。
リクエストが到達するとEnvoyが認証をフックし、検証に失敗した場合はEnvoyが直接クライアントに「401 Unauthorized」を返します。この認証オフロード(Authentication Offloading)により、開発者はビジネスロジックに専念でき、堅牢なゼロトラスト・アーキテクチャが実現します。
まとめ:401エラーの正しいハンドリングでセキュアな基盤を
「401 Unauthorized」は、単なるパスワードの打ち間違いエラーではなく、システムが誰を信用し誰を拒絶するかを制御する境界線の役割を果たします。
開発者やインフラエンジニアは、401と403の違いを理解し、JWTのライフサイクル管理、CORSの例外処理、SEOにおける構造化データの活用に至るまで、システム全体を俯瞰した設計を行わなければなりません。認証とセキュリティの土台を強固に築き上げ、最適なWebサービスを構築してください。
▼ あわせて読みたい(関連記事)
- 400 Bad Requestの原因と対処 – JWT肥大化とREST APIパースエラー
- 502 Bad Gatewayの解決ガイド – Nginxとバックエンドの通信障害
- 504 Gateway Timeoutの解決ガイド – ロードバランサーとタイムアウトの罠


とは?初心者向けに種類・選び方を解説.png)
