

アクセス急増で502エラーが表示された」等、Web運営にとって恐るべき機会損失のシグナルが「502 Bad Gateway」です。502はプロキシとアプリ間の連携断絶で発生します。
【結論】502 Bad Gatewayエラーとは?
一言で言えば、「窓口のサーバー(Nginx等)が、裏側の担当サーバー(PHP等)に処理を頼んだが、正しい返事が返ってこなかった」ことを示すサーバーエラーです。
- 主な原因: 裏側のプログラムが落ちている(ダウン)、またはアクセス急増で処理パンク(ワーカープロセスの枯渇)を起こしている。
- 解決策: サーバーに入ってエラーログを確認し、落ちているプロセスを再起動するか、処理の上限設定(チューニング)を引き上げる。
本記事では、Nginxのソケット枯渇、AWS ALBのタイムアウト設定の罠、Linuxカーネルのチューニングまで徹底解説します。
Google公式ガイドラインおよびRFC(インターネット技術標準)の見解
「502 (Bad Gateway) ステータスコードは、ゲートウェイまたはプロキシとして機能しているサーバーが、リクエストを満たそうとアクセスしたインバウンド・サーバー(上流サーバー)から無効な(invalid)応答を受け取ったことを示します。」
引用元:RFC 7231 – HTTP/1.1: Semantics and Content (Section 6.6.3)
- 502 Bad Gatewayエラーとは?
- システムアーキテクチャから紐解く「502 Bad Gateway」のメカニズム
- インフラエンジニア向け:502エラーの主要な原因とNginxのログ解析
- さらに高度なアーキテクチャ:LinuxカーネルチューニングとAWS/K8sのトラップ
- マイクロサービス・DB起因:インフラ深層部で連鎖する502エラー
- 一般ユーザー向け:ブラウザ側でできる502エラーの切り分け
- 502エラーとSEO:検索エンジンへの致命的なダメージと「503」への変更
- よくある質問(FAQ)と高度なインフラ的疑問
- 【専門家向け技術仕様】リバースプロキシのタイムアウト最適化とゼロダウンタイムデプロイメント
- まとめ:502エラーの根本原因を解消し、堅牢なインフラを構築しよう

502 Bad Gatewayエラーとは?
502 Bad Gatewayエラーをインフラの観点から端的に説明すると、「リバースプロキシ(窓口)がアップストリーム(裏側の担当者)と通信しようとしたが、正常な応答が得られなかった状態」を指します。
ブラウザの画面をリロードしても直ることは少なく、サーバー内部で以下のような異常事態が発生しているサインです。
- プロセスが落ちている: PHP-FPMやNode.jsなどのアプリケーションサーバーが異常終了(ダウン)している。
- リソースが枯渇している: アクセス急増により、裏側で処理できる人数(ワーカープロセス)の上限に達してしまい、新たなリクエストを拒否している。
システムアーキテクチャから紐解く「502 Bad Gateway」のメカニズム
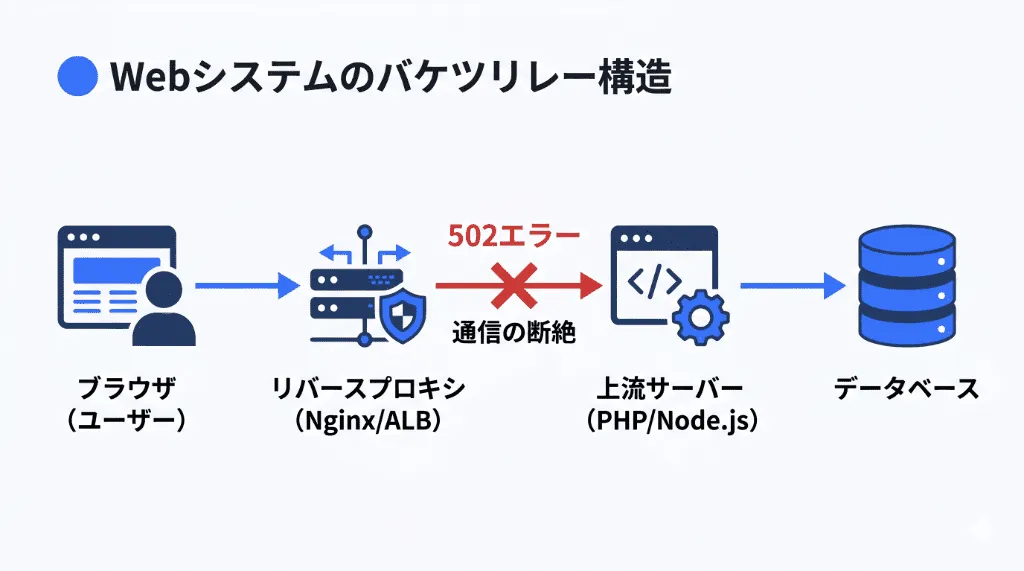
502エラーのデバッグを始める前に、まず「現代のWebシステムがどのように通信をバケツリレーしているのか」という構造を理解することが不可欠です。
リバースプロキシとアップストリーム(上流サーバー)の概念
ユーザーのブラウザから送信されたリクエストは、直接PHPやNode.jsのプログラムに到達するわけではありません。通常、その間には「リバースプロキシ(ゲートウェイ)」と呼ばれる門番が立っています。
[ユーザー (ブラウザ)]
│ (インターネット経由のHTTPリクエスト)
▼
[リバースプロキシ / ロードバランサー] (Nginx, AWS ALB, Cloudflare等)
│ (内部ネットワークでのソケット通信・プロキシ転送)
▼
[アプリケーションサーバー] (PHP-FPM, Node.js, Gunicorn, Tomcat等) <= ここを「アップストリーム(上流)」と呼ぶ
│ (SQLクエリ)
▼
[データベース] (MySQL, PostgreSQL等)
502エラーは、このバケツリレーにおいて、「リバースプロキシが、アプリケーションサーバーに仕事(リクエスト)を渡そうとしたが、アプリケーションサーバーが返事をしてくれなかった、あるいは中途半端な壊れたデータを返してきた」という瞬間に発生します。リバースプロキシはユーザーを待たせ続けるわけにはいかないため、「私の後ろにいる担当者(上流サーバー)がポンコツなので処理できませんでした」という報告をユーザーに返します。これが「502 Bad Gateway」です。
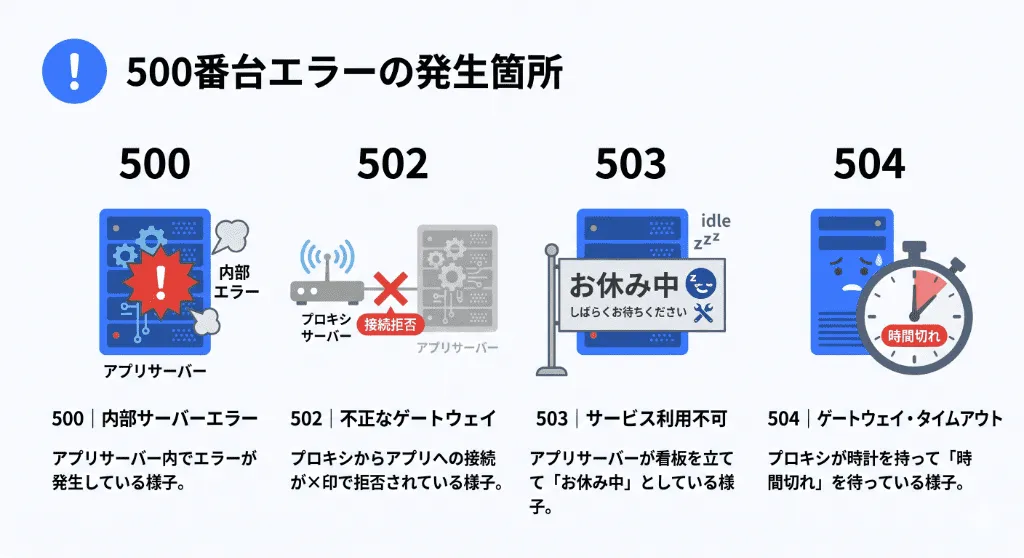
500番台エラーの切り分け(500 / 502 / 503 / 504)
| コード | 名称 | インフラ的な解釈(どこで何が起きたか) |
|---|---|---|
| 500 | Internal Server Error | プログラムのバグ(シンタックスエラー等)が発生し、アプリケーションサーバー側で処理がクラッシュした。 |
| 502 | Bad Gateway | リバースプロキシが上流に通信しようとしたが、通信が拒否された、または途中で強制切断された。 |
| 503 | Service Unavailable | サーバーがメンテナンス中、または過負荷によって自発的に「今は処理できません」と応答している状態。 |
| 504 | Gateway Timeout | 通信は確立したが、タイムアウト値を超過しても処理が終わらず返事が返ってこなかった。 |
インフラエンジニア向け:502エラーの主要な原因とNginxのログ解析
自社のサーバー(Linux)で502エラーが発生した場合、ブラウザの画面を眺めていても解決しません。真っ先にSSHでサーバーにログインし、/var/log/nginx/error.log などのプロキシ側のエラーログを確認する必要があります。
アプリケーションプロセスのダウン(Connection refused)
ログに connect() failed (111: Connection refused) while connecting to upstream と出力されている場合、原因は極めてシンプルです。「Nginxが指定されたポート(例:ポート9000番や3000番)にリクエストを転送しようとしたが、そのポートで待ち受けているはずのアプリケーションプロセス(PHP-FPMやNode.js)がそもそも起動していない、または落ちている」状態です。
解決策: systemctl status php-fpm や pm2 status コマンドでバックエンドのプロセスが生きているか確認し、落ちていれば systemctl restart php-fpm で再起動します。OOM Killer(メモリ不足によるOSからの強制終了)が発動していないか、/var/log/messages や dmesg コマンドでカーネルログも併せて確認します。
ワーカープロセスの枯渇・上限到達(Resource temporarily unavailable)
テレビ放映などでアクセスが急激に増加し、ログに connect() to unix:/run/php/php8.1-fpm.sock failed (11: Resource temporarily unavailable) while connecting to upstream が大量発生している場合、PHP-FPMなどのアプリケーションワーカープロセスがすべて出払ってしまい(満席状態)、新しいリクエストを受け付けられない状態です。
解決策(PHP-FPMのチューニング):/etc/php/8.1/fpm/pool.d/www.conf を開き、プロセスの上限を引き上げます。
pm = dynamic pm.max_children = 200 # デフォルトは5や50など。サーバースペック(メモリ量)に応じて増やす pm.start_servers = 20 pm.min_spare_servers = 10 pm.max_spare_servers = 30
※注意:max_children を無闇に大きくすると、今度はサーバー全体の物理メモリ(RAM)を食いつぶし、スワップが発生してサーバー全体が完全にフリーズ(ダウン)する危険性があります。「1プロセスあたりの平均メモリ消費量 × max_children < 総メモリ量」となるよう計算して設定してください。
Unixドメインソケットのパーミッションエラー(Permission denied)
NginxとPHP-FPMをTCP(127.0.0.1:9000)ではなく、高速なUnixドメインソケット(/run/php/php-fpm.sock)で接続している際、ログに Permission denied と出る場合は、Nginxの実行ユーザー(通常は www-data や nginx)が、そのソケットファイルに対する読み書き権限を持っていません。
PHP-FPM側の設定で listen.owner = www-data、listen.group = www-data が正しく指定されているか確認します。
さらに高度なアーキテクチャ:LinuxカーネルチューニングとAWS/K8sのトラップ
モダンなクラウドインフラ(AWS、Kubernetes)や高トラフィック環境においては、単なるプロセスの再起動では解決しない、より深いレイヤーでの502エラーが発生します。
Linuxカーネルのソケットキュー溢れ(somaxconnのチューニング)
NginxからPHPへのリクエストが殺到した際、PHP側が処理しきれずに「待ち行列(キュー)」に入ります。この待ち行列を入れる箱のサイズ(バックログ)は、Linuxカーネルの設定(net.core.somaxconn)によってOSレベルで上限が決められています(デフォルトは128など非常に小さい値です)。この箱から溢れたリクエストはすべてTCPレベルで破棄(Drop)され、Nginxは502エラーを返します。
解決策: Linuxのカーネルパラメータをチューニングします。/etc/sysctl.conf に以下を追加し、sysctl -p を実行します。
net.core.somaxconn = 4096 net.ipv4.tcp_max_syn_backlog = 4096
併せて、Nginx側(listen 80 backlog=4096;)とPHP-FPM側(listen.backlog = 4096)のバックログ設定も引き上げる必要があります。この3箇所をすべて揃えなければ効果は発揮されません。
AWS ALB(Application Load Balancer)とKeep-Aliveの不整合
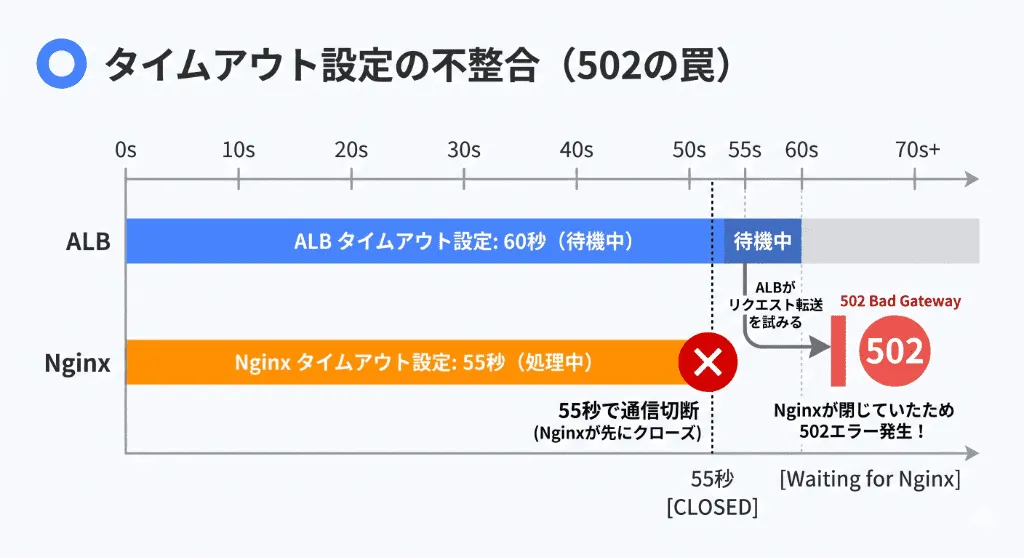
AWSインフラにおいて、「ELB/ALBを通すと502が出るが、EC2に直接アクセスすると正常」という極めて厄介な現象があります。これは、ALBとバックエンドのEC2(NginxやApache)との間の「Keep-Aliveタイムアウト設定の不整合」が原因です。
ALBはTCPコネクションを再利用しようとしますが、バックエンドのNginx(keepalive_timeout)がALBのアイドルタイムアウト値(デフォルト60秒)よりも短く設定されていると、ALBが「まだ通信できる」と思ってリクエストを投げた瞬間に、Nginx側が「もう時間が来たから」と一方的に通信を切断(Connection Closed)してしまいます。ALBはパニックになり、クライアントに502エラーを返します。
鉄則: バックエンドサーバーのKeep-Aliveタイムアウト値は、必ずロードバランサーのアイドルタイムアウト値よりも「長く」設定しなければなりません(例:ALBが60秒なら、Nginxは65秒にする)。
Kubernetes(K8s)のローリングアップデート時の502エラー
KubernetesでPod(コンテナ)の新しいバージョンをデプロイする際、数秒間だけ502エラーが多発することがあります。これは、Ingress(リバースプロキシ)からPodへのトラフィックのルーティング切り替えのタイミングと、コンテナ内のアプリケーション(Node.js等)がトラフィックを受け付ける準備(Readiness)が完了するタイミングにズレ(Race Condition)が生じているためです。
解決策としては、Podの設定(Deployment)において readinessProbe を厳格に設定し、アプリケーション側でシャットダウンシグナル(SIGTERM)を受け取った際に即座にプロセスを殺すのではなく、数秒間待機して現在処理中のリクエストを安全に返し終える「Graceful Shutdown(グレースフル・シャットダウン)」のロジックをソースコード内に実装する必要があります。
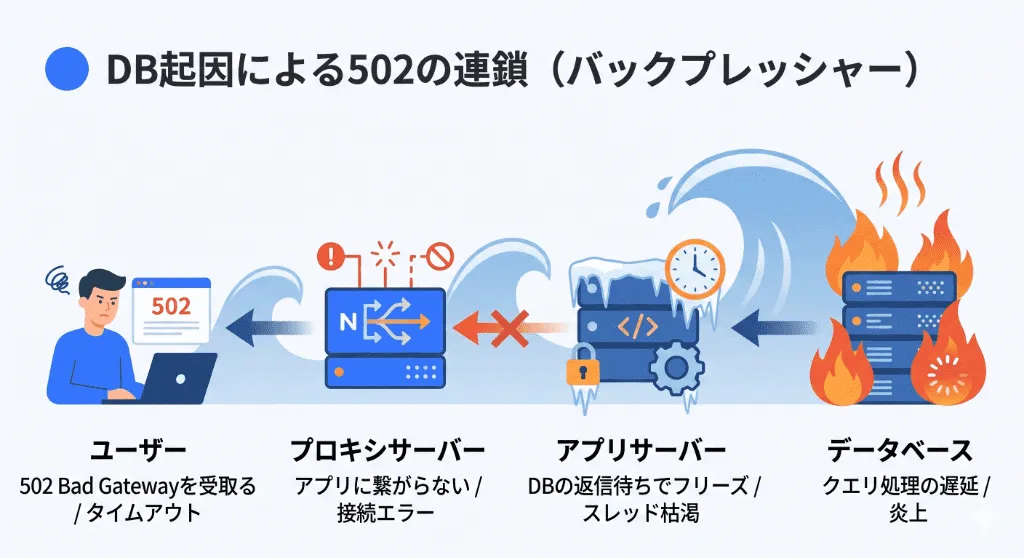
マイクロサービス・DB起因:インフラ深層部で連鎖する502エラー
502エラーの原因は、必ずしもリバースプロキシとWebサーバー(NginxとPHP等)の間にだけ存在するわけではありません。Webサーバーのさらに後方(バックエンド)に位置するデータベースや外部APIの障害が、ドミノ倒しのように連鎖して最前線の502エラーを引き起こすケースを解説します。
データベースのコネクションプール枯渇による「バックプレッシャー」
アプリケーションサーバーがデータベース(MySQLやPostgreSQL)に対してクエリを投げる際、都度TCP接続を確立するのはオーバーヘッドが大きいため、「コネクションプール(Connection Pool)」という仕組みを用いて接続を使い回します。
しかし、トラフィックが急増し、データベース側の処理能力(スロークエリなど)が追いつかなくなると、プール内のコネクションがすべて「使用中(Wait状態)」で埋め尽くされます。この状態(コネクション枯渇)に陥ると、アプリケーションサーバー(PHPやJava/Spring Boot)自体は生きていても、データベースからの応答待ちで身動きが取れなくなり、プロキシからの新規リクエストを処理できずに拒否(Connection Refused / Read Timeout)することになります。結果として、最上位のNginxやALBが「502 Bad Gateway」をユーザーに返します。
解決策: データベース側に問題がある場合、Webサーバーのプロセス上限を増やしても逆効果(さらなるDB負荷の増大)になります。HikariCP(Java)やpgBouncer(PostgreSQL)といったコネクションプーラーの設定を見直すとともに、不要なN+1クエリの撲滅、そしてRedisやMemcachedを用いたキャッシュ層の導入によってデータベース本体へのトラフィックを物理的に遮断するアーキテクチャへの改修が必要です。
Node.js(PM2/Express)固有のシングルスレッド限界と502
Node.jsは「ノンブロッキングI/O」と「シングルスレッド」という強力な非同期アーキテクチャを持っていますが、CPUバウンドな処理(巨大なJSONのパース、複雑な暗号化計算、画像処理など)を行うと、そのシングルスレッド(イベントループ)が完全にブロック(占有)されてしまいます。
イベントループがブロックされている数秒〜数十秒間、Node.jsはNginxからの新しいHTTPリクエストを受け付けることができません。結果としてNginx側がタイムアウト、または接続拒否と判断して502エラーを吐き出します。
解決策: この現象はPM2などのプロセスマネージャーを使用している環境で頻発します。PM2の Cluster Mode(クラスタモード) を有効化し、サーバーのCPUコア数と同じ数だけNode.jsプロセスをフォーク(立ち上げ)してロードバランシングさせること。そして、CPUを占有する重い処理は、RedisやAWS SQSを用いた「バックグラウンドワーカー(別プロセス)」に逃がす(非同期キュー処理にする)設計へのリファクタリングが不可避です。
一般ユーザー向け:ブラウザ側でできる502エラーの切り分け
502エラーはインフラの問題ですが、Webサービスを利用している一般ユーザー側でも、それが「自分だけの環境の問題なのか」「システム全体の障害なのか」を切り分ける方法があります。
キャッシュの強制クリア(スーパーリロード)
稀に、プロキシサーバー(Cloudflare等)が「502エラーの画面そのものをキャッシュ」してしまっている場合があります。障害は復旧しているのに、ブラウザのローカルキャッシュのせいでエラー画面が残り続けるケースです。
Windowsの場合は Ctrl + F5、Macの場合は Command + Shift + R を押して、強制的にサーバーから最新のデータを取得させてください。
Cloudflareの画面による「誰の責任か」の判別
対象のサイトがCloudflareというCDNを利用している場合、502エラーの際に特有のグラフィカルなエラー画面が表示されます。そこには「Browser(緑色)」「Cloudflare(緑色)」「Host(赤色・エラー)」といった図が描かれています。
もし「Host」側にエラーマークが付いている場合、それは「Webサイトの運営会社のサーバーが落ちている」ことを意味し、ユーザーとしては復旧を待つ以外に方法はありません。逆にCloudflare側にエラーがある場合は、世界規模のネットワーク障害が発生している可能性があります。
502エラーとSEO:検索エンジンへの致命的なダメージと「503」への変更
頻発する502エラーは、ユーザーからのクレームを生むだけでなく、企業のデジタル資産であるSEO(検索順位)に対しても壊滅的なダメージを与えます。
クロールバジェットの浪費とインデックスの削除
Googlebot(クローラー)は、サイトを巡回中に502エラーに遭遇すると、「このサーバーは不安定だ」と判断し、クロール頻度(クロールバジェット)を大幅に低下させます。これが数日間にわたって継続した場合、Googleのアルゴリズムは「このページは死んでいる(利用不能)」と認識し、検索結果(インデックス)からそのページを完全に除外(削除)します。
計画メンテナンス時の「503」の正しい運用
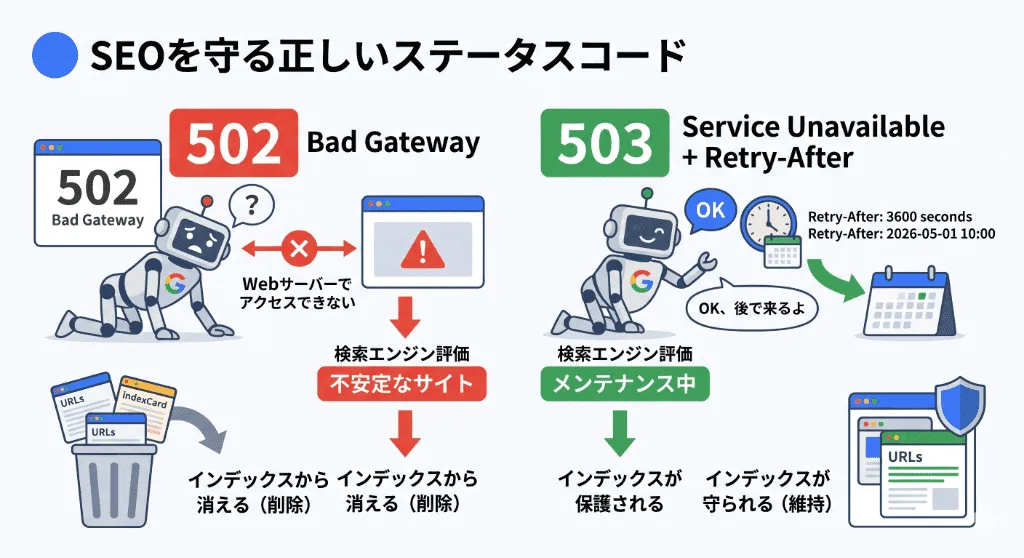
データベースの移行や大規模なサーバー改修を行う際、Nginxを適当に止めてユーザーに502エラーを見せるのは最悪の運用です。
計画的なメンテナンスを実施する場合は、リバースプロキシ(Nginx)の設定で、すべてのアクセスに対して明示的に「503 Service Unavailable(サービス一時停止中)」というステータスコードを返し、同時に Retry-After: 3600(1時間後に再アクセスしてほしい)というHTTPヘッダーを付与する設定を行ってください。
502が「通信の失敗・異常事態」を示すのに対し、503とRetry-Afterの組み合わせは、Googlebotに対して「今は意図的に閉めているだけだから、インデックスは消さずに後でまた来てね」という正しいメッセージ(SEO上の保護)を伝えることができます。
よくある質問(FAQ)と高度なインフラ的疑問
Q1. 502 Bad Gateway と 504 Gateway Timeout の根本的な違いは何ですか?
A. 「通信の拒否・切断」か、「返事待ちの限界」かの違いです。
502は、リバースプロキシが上流サーバーに接続しようとした瞬間に「拒否(Connection Refused)」されたり、処理中に突然プツンと回線を「切断(Connection Reset)」された場合に発生します(サーバーが落ちている、ソケットが枯渇している等)。
一方、504は通信自体は確立し、上流サーバーに「処理をお願い」したものの、Nginx側で設定された待ち時間(例:proxy_read_timeout 60s)を過ぎても、上流から全くデータが返ってこなかった(データベースのスロークエリ待ち等で永遠に固まっている)場合に「もう待てない」とプロキシ側がタイムアウトを宣告した状態です。
Q2. オートスケーリング(AWS Auto Scaling)を導入すれば502エラーは防げますか?
A. 突発的なアクセス(スパイク)に対しては、オートスケーリングだけでは防ぎきれません。
テレビ放映などでアクセスが数秒間で100倍になるような場合、AWSがCPU負荷を検知し、新しいEC2インスタンスを起動してロードバランサーに組み込むまでには数分間のタイムラグが発生します。その間に既存のサーバーのプロセスが枯渇し、大量の502エラーが発生します。
スパイクトラフィックを防ぐには、オートスケーリングに依存するだけでなく、CloudFront(CDN)を用いたキャッシュ戦略によるオリジンサーバーへの到達リクエストの削減や、Redisを用いたデータベース負荷のオフロード、さらにはAWS WAFのレートベースルールを用いた過剰なトラフィックの制限といった「多層的な防御アーキテクチャ」が必須となります。
Q3. アプリケーションサーバーのメモリ(RAM)を増やせば502エラーは減りますか?
A. 減る可能性はありますが、根本的な解決にならないことが多いです。
メモリを増やせば、PHP-FPMの max_children などのワーカープロセス上限を引き上げることができ、同時接続数を増やすことができます。しかし、プロセスが滞留している根本原因が「データベースのインデックス不足によるスロークエリ(遅いSQL)」や「外部APIの応答遅延」である場合、どれだけワーカープロセスを増やしても、それらがすべて「待ち状態」になるだけであり、最終的にはプロセスが枯渇して再び502エラーが発生します。インフラの増強(スケールアップ)は最終手段とし、まずはアプリケーションのプロファイリング(ボトルネックの特定)を行うべきです。
【専門家向け技術仕様】リバースプロキシのタイムアウト最適化とゼロダウンタイムデプロイメント
本セクションでは、単なるサーバー再起動といった対症療法を超え、月間数千万トラフィックを処理するエンタープライズインフラにおいて必須となる、リバースプロキシ(Nginx / HAProxy / Envoy等)の高度なルーティング制御と、502エラーを根絶するためのアーキテクチャについて解説します。
NginxにおけるUpstream接続のタイムアウト最適化とバッファチューニング
502 Bad Gatewayが多発する最も技術的な要因の一つは、リバースプロキシ(フロントエンドのWebサーバー)とUpstream(背後のアプリケーションサーバー群:Node.js、Gunicorn、PHP-FPMなど)間の「通信の非同期性」や「TCPコネクションのタイムアウト設定の不一致」にあります。たとえば、バックエンドの重いデータベースクエリに60秒かかる処理があるにもかかわらず、Nginx側の `proxy_read_timeout` がデフォルトの60秒未満(例:30秒)に設定されている場合、Nginxはバックエンドからの応答を待ちきれずコネクションを強制切断し、ユーザーに対して即座に502エラーを返却してしまいます。
これを防ぐためには、単にタイムアウトを長く設定するのではなく、各マイクロサービスやAPIエンドポイントの特性(SLA:Service Level Agreement)に応じたミリ秒単位でのタイムアウトチューニングが必要です。また、バックエンドから返される巨大なJSONやHTMLペイロードをNginx側で効率的に受け取るための `proxy_buffer_size` や `proxy_buffers` のメモリ最適化を行うことで、通信プロセス(ソケット)の溢れ(Buffer Overflow)に起因する突発的な502エラーをシステムレベルで抑え込むことが可能になります。
ヘルスチェック自動化とブルーグリーンデプロイメントによる無停止更新
アプリケーションのバージョンアップ(新しいコードのデプロイ)時に、バックエンドサーバーのプロセスが再起動する数秒間、アクセスしたユーザーに502エラーが表示されてしまう問題は、ECサイト等のコンバージョン率に致命的な影響を与えます。高度なDevOps環境では、このデプロイに伴う「瞬断」を完全にゼロにするためのアーキテクチャが構築されています。
具体的には、KubernetesやAWS ALB(Application Load Balancer)のレイヤーで「アクティブヘルスチェック」を常時実行します。これは、ロードバランサーが数秒に1回、バックエンドの特定のパス(例:`/health`)へPingを送り、HTTP 200 OKが返ってくるかを監視する仕組みです。新しいバージョンのコンテナ(グリーン環境)を立ち上げ、ヘルスチェックが完全にパスしたことを確認してから、トラフィックのルーティングを古いバージョン(ブルー環境)からシームレスに切り替えます。万が一、新しいコンテナが起動に失敗し、Upstreamとの通信が確立できない場合(502の予兆)でも、ルーティングの切り替えは自動でキャンセルされるため、ユーザー側に502エラーが露出することは絶対にありません。こうした「ゼロダウンタイムデプロイメント」のインフラ構築こそが、強固なSEOとUXを支える基盤となります。
eBPFを用いたLinuxカーネルレベルでのパケットドロップ監視と502解析
秒間数万リクエストを処理するハイトラフィック環境で発生する「瞬断による502エラー」は、アプリケーションログ(NginxやPHP-FPMのアクセスログ)には全く記録されないことが多く、原因特定が極めて困難です。これは、OS(Linuxカーネル)のTCPソケットキュー(somaxconn)が溢れ、カーネルレベルでパケットが「Drop(破棄)」されているために起こります。
最新のオブザーバビリティ(可観測性)基盤では、「eBPF(Extended Berkeley Packet Filter)」という技術を活用します。eBPFを用いることで、カーネルのソースコードを変更することなく、TCPのSYNパケットがドロップされた瞬間や、TCP再送(Retransmission)が発生した正確なタイミングをマイクロ秒単位で安全にフック(監視)できます。このカーネルレベルのメトリクスをPrometheusやGrafanaに連携させることで、アプリケーション層からは不可視だった「インフラ深層部でのネットワーク目詰まり」を瞬時に可視化し、502エラーの根本原因であるソケット枯渇をプロアクティブに解消することが可能になります。
まとめ:502エラーの根本原因を解消し、堅牢なインフラを構築しよう
「502 Bad Gateway」は、単なるサーバーの一時的な不調ではありません。それは、ロードバランサーからデータベースに至るまでの複雑なネットワーク・バケツリレーのどこかに、「トラフィックを捌ききれないボトルネック」が存在しているという、システムからの重大な悲鳴(アラート)です。
インフラエンジニアは、エラーログを注意深く読み解き、それが「プロセスの枯渇」なのか「タイムアウト設定の不整合」なのか「Linuxカーネルのソケット制限」なのかを論理的に特定する必要があります。そして、一時的なプロセスの再起動(サービスのリスタート)でその場を凌ぐのではなく、Nginxのチューニングや、Kubernetesのグレースフルシャットダウンの実装といった「アーキテクチャレベルの改善」を施すことで初めて、高いSLA(サービス品質保証)を達成することができます。
エラー画面を放置することは、売上の機会損失とSEO評価の失墜に直結します。本記事のデバッグ手順を活用し、予測不可能な高負荷にも耐えうる、堅牢でスケーラブルなWebインフラを構築してください。
あわせて読みたい(関連記事)
502エラーとセットで発生しやすいその他の重要ステータスコードや、インフラ・開発設計に関する専門ガイドも併せてご活用ください。
▶︎ 504 Gateway Timeoutの解決ガイド – ロードバランサーとタイムアウトの罠
▶︎ 400 Bad Requestの原因と対処 – JWT肥大化とREST APIパースエラー



