

バッチ処理や重いデータエクスポート時に発生し、エンジニアを悩ませる「504 Gateway Timeout」。このエラーは「通信は確立しているが、処理が終わらない」というバックエンドの遅延に起因するインフラ障害です。
【端的な結論】504 Gateway Timeoutエラーとは?
一言で言えば、「窓口のサーバー(Nginx等)が裏側の担当サーバー(PHP等)に仕事を頼んだが、制限時間(タイムアウト)を過ぎても返事が来なかった」ことを示すエラーです。
- 主な原因: データベースのスロークエリ、外部APIの障害・遅延、時間がかかる重い処理(CSV出力など)を同期的に実行していること。
- 解決策: 処理のボトルネックを特定して軽量化する、NginxやALBのタイムアウト設定時間を延長する、または「非同期処理(キュー)」へアーキテクチャを移行する。
本記事では、502エラーとの決定的な違いから、Nginxのタイムアウト設定、MySQLのデッドロック、AWS ALB特有の罠、非同期アーキテクチャへの移行まで徹底解説します。
Google公式ガイドラインおよびRFC(インターネット技術標準)の見解
「504 (Gateway Timeout) ステータスコードは、ゲートウェイまたはプロキシとして機能しているサーバーが、リクエストを完了するためにアクセスする必要があるアップストリームサーバー(URIによって指定されたサーバーやその他の補助サーバーなど)から、適時に(timely)応答を受け取らなかったことを示します。」
引用元:RFC 7231 – HTTP/1.1: Semantics and Content (Section 6.6.5)
- 504 Gateway Timeoutエラーとは?(502との違い)
- インフラエンジニア向け:504エラーの主要な原因とNginxのチューニング
- さらに高度なアーキテクチャ:スロークエリ・外部API・AWS ALBの罠
- 非同期処理へのアーキテクチャ移行(504の根本的解決)
- 一般ユーザー向け:ブラウザ側でできる504エラーの切り分け
- 504エラーとSEO:検索エンジンへの致命的なダメージと「503」への変更
- エンタープライズ向け:APMを用いた504エラーの分散トレーシング(可視化)
- よくある質問(FAQ)と高度なインフラ的疑問
- 【専門家向け技術仕様】コネクションプーリング最適化とインメモリキャッシュによる504回避アーキテクチャ
- まとめ:504エラーは「アーキテクチャの改善」で根本解決しよう

504 Gateway Timeoutエラーとは?(502との違い)
504エラーのデバッグを始める前に、「現代のWebシステムにおけるタイムアウトという概念」をインフラ的視点から正確に理解する必要があります。
プロキシとアップストリーム(上流サーバー)の「待ち時間」
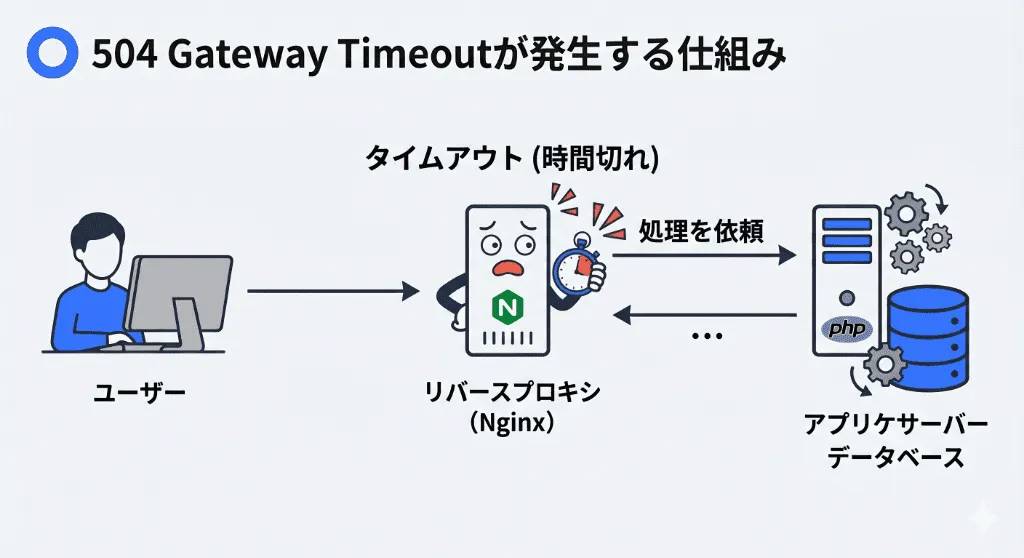
現代のWebサイトは、単一のサーバーで動いているわけではありません。ユーザーのブラウザと、実際のプログラムが動くサーバーの間には、必ず「リバースプロキシ(ゲートウェイ)」が存在します。
[ユーザー (ブラウザ)]
│ (HTTPリクエスト)
▼
[リバースプロキシ / ロードバランサー] (Nginx, AWS ALB, Cloudflare等)
│ (プロキシは「ストップウォッチ」を押して待機を開始)
▼
[アプリケーションサーバー] (PHP-FPM, Node.js, Gunicorn等)
│ (重い処理:画像リサイズ、外部API通信、複雑なSQL)
▼
[データベース] (MySQL, PostgreSQL等)
504エラーは、このバケツリレーにおいて、「リバースプロキシが、アプリケーションサーバーに処理を依頼し、ストップウォッチで計っていた制限時間(例:60秒)を過ぎても、アプリケーションサーバーから一切返事が来なかった」という瞬間に発生します。
プロキシサーバーはユーザーを無限に待たせるわけにはいかない(コネクションを占有され続けると自分自身がパンクする)ため、「上流の担当者からの返事が遅すぎるため、処理を強制的に打ち切りました」という報告をユーザーに返します。これが「504 Gateway Timeout」です。
502(Bad Gateway)と504(Gateway Timeout)の決定的な違い
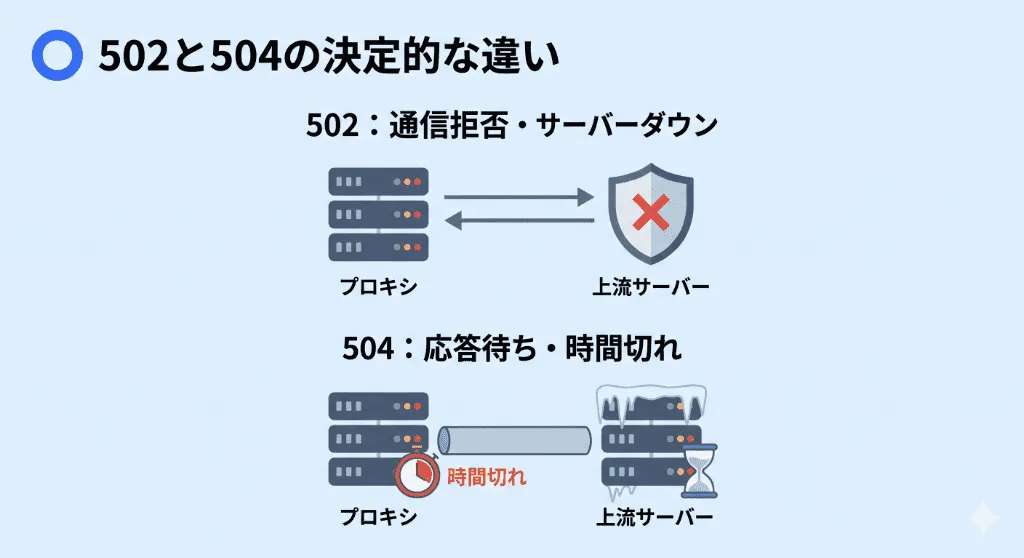
502と504は混同されがちですが、インフラ層で起きている事象は「真逆」と言っていいほど異なります。
| コード | 名称 | インフラ的な解釈(どこで何が起きたか) |
|---|---|---|
| 502 | Bad Gateway | 上流に接続しようとしたが即座に拒否されたか、途中で強制切断された。上流のプロセスが落ちている状態。 |
| 504 | Gateway Timeout | 接続自体は正常に確立したが、上流が沈黙したままタイムアウト設定を超過した。プロセス自体はフリーズして生きている状態。 |
つまり、504エラーを解決するためのアプローチは「落ちているサーバーを再起動する」ことではなく、「なぜその処理にそんなに時間がかかっているのか(ボトルネックの特定)」、または「タイムアウトの設定値は適切か」を検証することになります。
インフラエンジニア向け:504エラーの主要な原因とNginxのチューニング
自社のサーバーで504エラーが発生した場合、まずはプロキシ(NginxやApache)のタイムアウト設定と、アプリケーション(PHP等)の処理時間の「競合」を疑います。
Nginxのタイムアウトディレクティブの使い分け
Nginxには、タイムアウトを制御するためのディレクティブ(設定項目)が複数存在します。これらを正しく理解せずに、適当に数値を増やすのは非常に危険です。
| ディレクティブ | 役割と設定のポイント |
|---|---|
| proxy_connect_timeout | Nginxが上流サーバーと「TCP接続を確立するまで」の待機時間。通常はデフォルトの60秒から増やす必要はありません。 |
| proxy_send_timeout | Nginxが上流サーバーに対して「リクエストデータを送信する際」のタイムアウト時間。 |
| proxy_read_timeout | 【最重要】Nginxがリクエストを送り終わった後、上流サーバーからのレスポンスを待つ時間。504エラーの9割はこれに起因します。 |
| fastcgi_read_timeout | バックエンドがPHP-FPMなどのFastCGIプロセスの場合に適用されます。 |
Nginxの修正例(nginx.conf または 各serverブロック):
重い処理(CSVエクスポートなど)が存在する特定のパスに対してのみ、タイムアウトを延長するのがベストプラクティスです。
location /api/heavy-export/ {
# 処理の重いパスだけ、待機時間をデフォルトの60秒から300秒(5分)に延長
proxy_read_timeout 300s;
fastcgi_read_timeout 300s;
proxy_pass http://backend;
}
PHPの「max_execution_time」とNginxのタイムアウトのレースコンディション
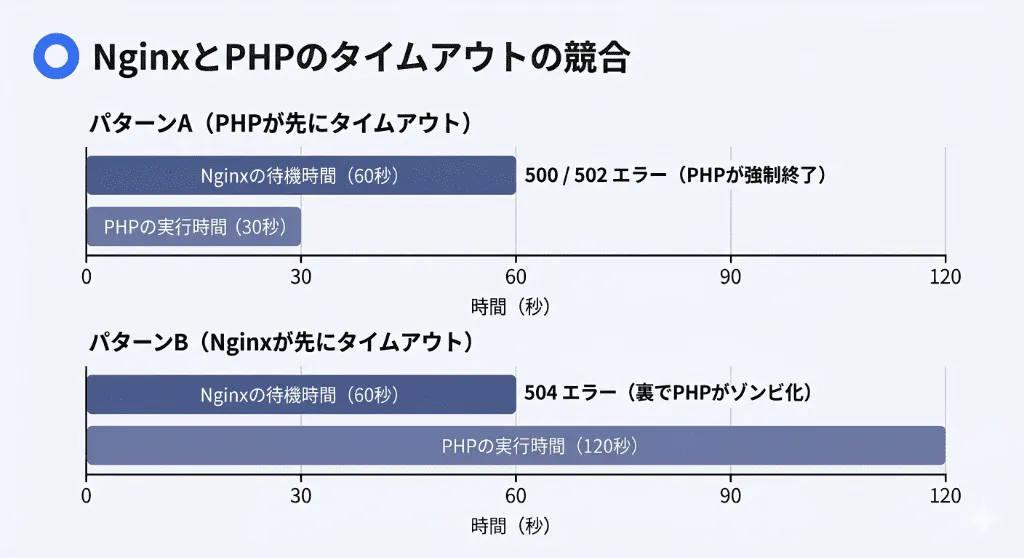
バックエンドがPHPの場合、PHP側にも「このスクリプトは最大〇〇秒までしか実行してはいけない」という制限(max_execution_time)が存在します。ここで、Nginx側とPHP側で設定値の競合(レースコンディション)が発生します。
- パターンA(PHPが先にタイムアウトする):
max_execution_time = 30、Nginxのfastcgi_read_timeout = 60の場合。30秒経過した時点でPHPのプロセスが自らを強制終了(Fatal Error)させます。この時、PHPからNginxには「エラーで落ちました」という不正な応答が返るため、ユーザーには 500 Internal Server Error または 502 Bad Gateway が表示されます。 - パターンB(Nginxが先にタイムアウトする):
max_execution_time = 120、Nginxのfastcgi_read_timeout = 60の場合。60秒経過した時点で、Nginxは「もう待てない」と判断し、クライアントとの通信を切断して 504 Gateway Timeout を返します。(※この時、背後のPHPプロセスはユーザーに返事が届かないにも関わらず、120秒になるまで無駄な処理を裏で継続(ゾンビ化)し、サーバーリソースを食いつぶすという最悪の事態を引き起こします)。
解決策の鉄則: 必ず PHP側の実行時間(max_execution_time) ≦ Nginxの待機時間(fastcgi_read_timeout) となるように設定を設計しなければなりません。
さらに高度なアーキテクチャ:スロークエリ・外部API・AWS ALBの罠
タイムアウト時間を無闇に延長する(例:600秒などにする)ことは、DDoS攻撃に対する耐性を著しく下げる「最悪のアンチパターン」です。根本原因である「バックエンドの遅延」を解消しなければなりません。
データベース(MySQL/PostgreSQL)のデッドロックとスロークエリ
アプリケーションサーバーがデータベースに対してクエリを投げた際、以下のような事象が発生すると、アプリケーションはDBからの返事を永遠に待ち続けることになり、結果としてNginxが504エラーを出力します。
- インデックス不足によるフルテーブルスキャン: 数百万レコードあるテーブルに対してインデックスなしで検索(JOIN)を行い、クエリの返却に数十秒かかっている状態。MySQLの
slow_query_logを有効化し、EXPLAINコマンドでボトルネックとなっているクエリを特定・チューニングする必要があります。 - トランザクションのデッドロック・ロック待ち: 行レベルロック(InnoDB等)において、複数のプロセスが互いにロックの解放を待ち合う「デッドロック」に陥った場合、設定された
innodb_lock_wait_timeout(デフォルト50秒)に達するまで処理が停止します。
サードパーティ(外部API)の障害やレートリミットによる道連れ
決済API(Stripe等)や、外部のSaaS連携APIを叩く際、その外部サービス側で障害が発生してレスポンスが極端に遅くなっている場合、自社のアプリケーションプロセスもその返事を待ってフリーズしてしまいます。自社システムは正常なのに、外部システムの遅延に道連れにされて504エラーになるケースです。
解決策: 外部APIを呼び出す関数(Guzzle、Axios、cURL等)には、必ずシステム全体のタイムアウトよりも短い「専用のクライアントタイムアウト(例:5秒)」をハードコードで設定し、タイムアウトした場合は「現在決済システムが混雑しています」という独自のハンドリング(例外処理)を行う防波堤の設計(Circuit Breakerパターン)が必須です。
AWS ALB(Application Load Balancer)のアイドルタイムアウトの罠
AWSインフラを利用している場合、「Nginxのタイムアウトを300秒に延ばしたのに、きっちり60秒で504エラーが出る」という現象が多発します。これは、AWS ALB自体の「アイドルタイムアウト(Idle Timeout)」の初期値が60秒に設定されているためです。
Nginxがどれだけ待つ設定になっていようと、その前段にいるALBが「バックエンドのEC2から60秒間通信がないので、通信を強制切断します」と判断し、クライアントに 504 Gateway Timeout を返してしまいます。
解決策: AWSコンソールのALBの設定画面(Attributes)から、Idle Timeoutの値をバックエンドの最大処理時間に合わせて延長(例:120秒や300秒など)する必要があります。
非同期処理へのアーキテクチャ移行(504の根本的解決)
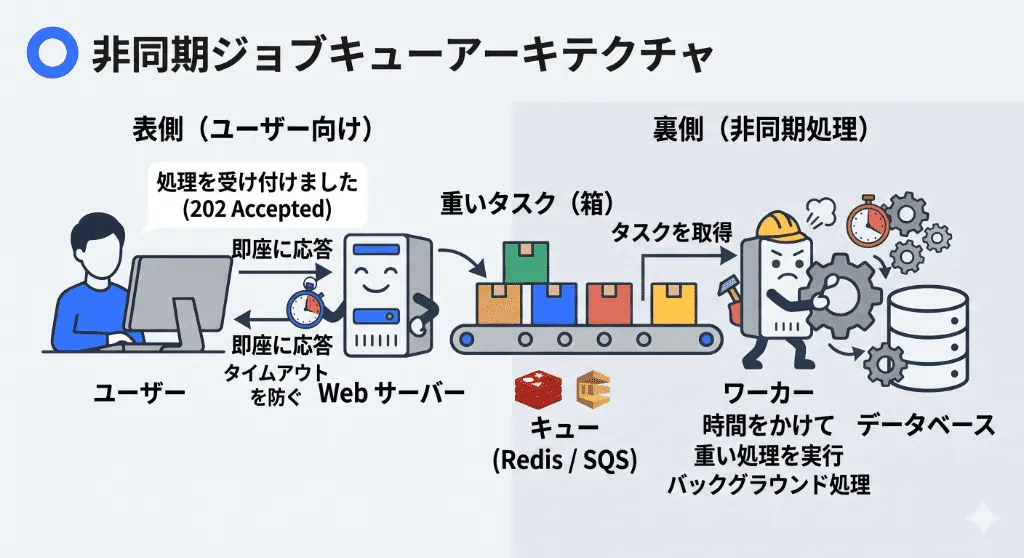
PDFの生成、大量のメール送信、数十万件のCSVインポートなど、物理的に数分以上の時間がかかる処理を、ユーザーがブラウザでボタンを押した「同期処理(HTTPリクエスト内)」の中で実行しようとすること自体が、Webアーキテクチャのアンチパターンです。
根本的な解決策:非同期ジョブキュー(Asynchronous Job Queue)パターンの導入
時間がかかる処理を要求された場合、Webサーバー(PHPやNode.js)は、そのタスクを「Redis」や「AWS SQS(Simple Queue Service)」などのキューに投げ込み、即座に「処理を受け付けました(ステータス202 Accepted)」とユーザーにレスポンスを返します(数ミリ秒で完了するため504エラーは必ず出ない)。
実際の重い処理は、バックグラウンドで動いている別の「ワーカープロセス(デーモン)」がキューからタスクを取り出して時間をかけて実行します。ユーザーにはフロントエンド(JavaScript)を通じて、WebSocketやポーリングで「処理が完了しました」と通知するUI(プログレスバーなど)を提供します。これが、モダンなSaaSにおける504エラー撲滅の最終形態です。
一般ユーザー向け:ブラウザ側でできる504エラーの切り分け
504エラーはインフラのパフォーマンス問題ですが、Webサービスを利用している一般ユーザー側でも、それが「一時的なものか」「致命的な障害か」を切り分ける方法があります。
時間を置いたアクセスと、二重決済への注意
504エラーは「サーバーが処理に苦しんでいる(遅い)」状態です。そのため、F5キー(更新)を連打することは、苦しんでいるサーバーにさらなる重い処理を追加で投げつけることになり(DDoS攻撃と同じ状態)、状況を悪化させます。
また、ECサイトで「注文を確定する」ボタンを押した後に504エラーが出た場合、必ずブラウザの「戻る」や「更新」を押してはいけません。 画面上はタイムアウトエラーに見えても、バックエンドのデータベースや決済APIの処理は裏でひっそりと完了(コミット)しているケースがあり、再送すると二重決済や二重発注のリスクが生じます。必ず、登録したメールアドレスに注文完了メールが届いていないか確認し、しばらく時間(10分〜30分程度)を空けてからマイページ等で状況を確認してください。
ネットワーク環境の切り替え
非常に稀ですが、自宅や社内のWi-Fiルーター、あるいはISP(プロバイダ)のDNSやプロキシサーバーが原因で通信経路が途絶え、504エラーが引き起こされているケースがあります。スマートフォンのWi-Fiを切り、4G/5G(モバイルデータ通信)に切り替えてアクセスし、正常に表示されれば、自身のネットワーク環境に問題があると特定できます。
504エラーとSEO:検索エンジンへの致命的なダメージと「503」への変更
サイト全体が重く、504エラーが慢性的に発生している状態は、SEO(検索順位)に対して最も悪影響を与える状態の一つです。
クロールバジェットの浪費と順位下落
Googlebot(クローラー)は、1つのサイトに滞在してクロールする時間的リソース(クロールバジェット)に上限を設けています。ページの読み込み(TTFB)に何十秒もかかり、結果的に504エラーを返すようなサイトは、クロールバジェットを著しく浪費します。Googleは「このサイトはユーザビリティが極めて低く、サーバーが限界に達している」と判断し、クロール頻度を激減させ、最終的には検索順位のペナルティ(下落)やインデックスの除外を実行します。Core Web Vitalsの指標悪化にも直結するため、即座にインフラを増強すべきです。
メンテナンス時には「503」を明示する
データベースの移行などで一時的に重くなることが分かっている場合は、ユーザーに504エラーやタイムアウトを経験させるのではなく、プロキシ(Nginx)側で一時的にサイトを遮断し、明示的に「503 Service Unavailable」ステータスを返す設定に切り替えるべきです。
503ステータスと共に Retry-After ヘッダーを返すことで、Googlebotに対して「今はメンテナンス中だから、インデックスは落とさずに後でまた来てね」という正しいシグナルを送り、SEO上のダメージをゼロに抑えることができます。
エンタープライズ向け:APMを用いた504エラーの分散トレーシング(可視化)
単一のサーバーであればNginxとPHPのログを突き合わせるだけで原因は特定できますが、現代のマイクロサービスアーキテクチャ(API Gateway、複数のコンテナ、外部SaaS連携が入り乱れる環境)において、どこで何秒滞留して504エラーになったのかを「テキストログ」だけで追跡するのは人間の限界を超えています。
APM(Application Performance Monitoring)の必須化
504エラーの根本解決において最も強力な武器となるのが、DatadogやNew Relic、Dynatraceといった「APMツール」です。
APMを導入すると、システムに送られた1つのHTTPリクエストに対して一意の「Trace ID(トレースID)」が発行されます。このTrace IDは、ロードバランサーを通り抜け、Nginx、Node.js、そして最終的なMySQLのクエリに至るまで、すべての通信を串刺しにして記録(分散トレーシング)します。
504エラーが発生した場合、APMのダッシュボードでそのリクエストの「フレームグラフ(処理時間の内訳図)」を見るだけで、
「フロントのNginxでは60秒でタイムアウトしているが、裏ではPayment API(外部決済)の呼び出し処理が59.9秒間フリーズしていた」
という事実が一瞬で可視化されます。これにより、「インフラエンジニアとアプリケーションエンジニアが互いに責任を押し付け合う」という不毛な議論を排除し、即座に外部APIへのタイムアウト設定の見直しという具体的なコード修正へ移行できます。
スロークエリの自動検知とデータベースプロファイリング
504エラーのもう一つの元凶である「データベースの遅延」についても、モダンなAPMは非常に優れた効力を発揮します。
従来の運用では、MySQLの `slow_query_log` を有効にして、夜間に巨大なテキストファイルを解析ツール(pt-query-digest等)にかけてボトルネックを探すという泥臭い作業が必要でした。しかし、APMのデータベースプロファイリング機能を活用すれば、「どのエンドポイント(URL)から呼ばれた、どのSQL文が、具体的に何ミリ秒かかっているか」がリアルタイムでランキング化されます。
「毎朝9時の出社時間帯だけ、社内システムで従業員の勤怠打刻APIが504エラーになる」という事象に対しても、「usersテーブルへのJOINに適切なインデックスが張られておらず、1回の打刻処理に15秒かかっており、それが100人同時に発生した結果、データベースのコネクションが枯渇して全リクエストがタイムアウトしていた」という真のボトルネックを、障害発生の数分後には特定できるのです。
よくある質問(FAQ)と高度なインフラ的疑問
Q1. 504 Gateway Timeout が出たとき、サーバーのCPU使用率は100%になっていますか?
A. なっている場合と、全く平穏な(0%に近い)場合があります。
画像処理や動画エンコードなど、自社サーバーのリソースを食い潰す処理でタイムアウトした場合はCPUが100%に張り付きます。しかし、「データベースのスロークエリ(DB側の負荷)」や「外部の決済APIの応答遅延」が原因で待機している場合は、Webサーバー自体のCPUは全く使われておらず、ただメモリ上にプロセスを保持したまま「アイドリング(待ち状態)」になっているだけです。ここを勘違いしてWebサーバーのCPUを増強しても、全く解決になりません。
Q2. Nginxのタイムアウトを無限大(無制限)に設定しても良いですか?
A. 必ずやってはいけません。セキュリティと安定性における最悪のアンチパターンです。
タイムアウトを極端に長く(例:1時間など)設定すると、Slowloris攻撃などの「意図的に非常にゆっくり通信を行うDoS攻撃」に対して完全に無防備になります。悪意のあるユーザーが少しずつリクエストを送り続けるだけで、Nginxのワーカープロセスがすべて占有されてしまい、正常なユーザーからのアクセスを一切受け付けられなくなります。長時間の処理は必ずバックグラウンド(非同期キュー)に逃がすべきです。
Q3. Cloudflareを経由すると「Error 524: A timeout occurred」が出ます。これは504ですか?
A. はい、実質的に504エラーと同じですが、Cloudflare独自のステータスコードです。
Cloudflareは、オリジンサーバー(あなたのサーバー)に対してリクエストを送り、100秒間(Enterpriseプラン以外の上限)返事がなかった場合、独自の「524 A timeout occurred」というエラー画面を表示します。これは、あなたのサーバーとCloudflare間の通信は正常に確立しているが、あなたのサーバーの処理が100秒を超えたことを意味します。対処法は本記事の504エラーの解決策と全く同じです。
【専門家向け技術仕様】コネクションプーリング最適化とインメモリキャッシュによる504回避アーキテクチャ
本セクションでは、単純なタイムアウト設定の延長やサーバーの再起動を超え、大規模なトラフィックや複雑なクエリ処理が常態化するエンタープライズシステムにおいて、504 Gateway Timeoutを根底から根絶するためのバックエンドアーキテクチャ(データベースとキャッシュ層の分離)について高度な視点から解説します。
データベースのコネクションプーリングとスロークエリの劇的な改善
504エラーが発生する最も致命的なボトルネックは、Webサーバー(Nginx等)からアプリケーションサーバー(PHP/Python/Node.js等)を経由して、最終的なデータベース(MySQLやPostgreSQLなど)へ到達した際のリソース枯渇(Connection Exhaustion)です。Webサイトにアクセスが殺到した際、アプリケーションがデータベースに対して毎回新規のTCP接続を確立しようとすると、データベース側の上限接続数(max_connections)に即座に達してしまい、後続のリクエストは接続待ち状態のまま数十秒間タイムアウト(504)へと追いやられます。
このアーキテクチャの欠陥を解決するためには、アプリケーションとデータベースの間に「PgBouncer(PostgreSQL用)」や「ProxySQL(MySQL用)」といった「コネクションプーラー(Connection Pooler)」のミドルウェア層を構築します。これにより、データベースへの物理的な接続を一定数(例:100個)に制限したまま維持し、数万のフロントエンドからのリクエストを効率的に再利用(多重化)することが可能になります。さらに、数千万件のレコードを処理する際に発生する「スロークエリ(応答に数秒かかる重いSQL)」に対しては、実行計画(EXPLAIN)を用いたインデックスの張り直しや、パーティショニング(テーブル分割)といった泥臭いDBチューニングを施すことが、504エラーを抜本的に解決する唯一の手段となります。
Redis / MemcachedによるインメモリキャッシュレイヤーでのDB負荷分散
どれほどデータベースのチューニングを行っても、ディスクI/O(ストレージの読み書き)が伴う以上、物理的な応答速度(ミリ秒単位の限界)は存在します。そのため、ECサイトのトップページや、更新頻度の低いコラム記事など、毎回データベースに問い合わせる必要のない「参照系(Read-heavy)のリクエスト」に対しては、データベースの前に「Redis」や「Memcached」といったキーバリューストア(KVS)型のインメモリキャッシュレイヤーを配置するアーキテクチャが必須となります。
一度データベースから取得した結果(HTMLのパーツやJSONデータ)を、超高速なRAM(メモリ)上に一定時間(TTL:Time To Live)キャッシュしておくことで、次に同じリクエストが来た場合は、データベースへクエリを投げることなく、Redisから数ミリ秒(マイクロ秒レベル)でデータを直接返却します。
これにより、データベースサーバーのCPU負荷やI/Oを劇的に引き下げ、浮いたリソースを決済処理や検索処理などの「真に重い動的処理」へ割り当てることが可能になります。システム全体の「応答の余裕(キャパシティ)」を生み出すこのキャッシュ戦略こそが、トラフィックのスパイク(急増)時における504 Gateway Timeoutを未然に防ぎ、クローラーに対して常に最速のUXを提供する極めて強力なインフラ陣地となるのです。
分散トレーシング(OpenTelemetry)によるマイクロサービス間のタイムアウト特定
現代のKubernetes(K8s)ベースのマイクロサービスアーキテクチャでは、1つのユーザーリクエストが背後の5つ以上のAPI(認証、決済、在庫確認など)をバケツリレーのように経由します。この環境下で504エラーが発生した場合、どのAPIがボトルネックになって全体のタイムアウトを引き起こしたかを特定するのは至難の業です。
そこで必須となるのが「OpenTelemetry(OTel)」などのオープン標準を用いた「分散トレーシング」の実装です。各サービス間にまたがるリクエストに単一の「Trace ID」を付与し、各スパン(処理区間)の所要時間をJaegerやDatadogなどのバックエンドに送信します。これにより、「Nginxから受けたリクエスト全体は60秒でタイムアウトしたが、実は決済APIと外部カード会社の通信で59秒間スタック(滞留)していた」という深層の原因がフレームグラフ上で一目瞭然となります。タイムアウトの連鎖(Cascading Failures)を防ぐため、この可視化基盤と連携した「Circuit Breaker(サーキットブレーカー)」の自動発動ロジックをサービスメッシュ層に組み込むことが、エンタープライズ規模のシステムにおける504エラー根絶の鍵となります。
まとめ:504エラーは「アーキテクチャの改善」で根本解決しよう
「504 Gateway Timeout」は、単なるサーバーの一時的な不調ではありません。それは、アプリケーションの処理フローの中に「リアルタイム(同期)で処理すべきではない重いタスク」が混入している、あるいは「データベースの設計(インデックス)に致命的な欠陥がある」という、システムからの警告です。
インフラエンジニアや開発者は、エラーログやAPM(DatadogやNew Relicなど)を活用して、リクエストが「Nginx」「PHP」「MySQL」「外部API」のどこで何秒間スタック(滞留)しているのかを論理的にプロファイリングする必要があります。
そして、一時的な解決策としてNginxやALBのタイムアウト設定を数秒延ばすことは許容されますが、最終的なゴールは「非同期アーキテクチャへのリファクタリング」や「クエリの最適化」を実行し、どんなリクエストに対しても数ミリ秒〜数百ミリ秒で確実に応答できる、堅牢でスケーラブルなWebシステムを再構築することです。
エラー画面を放置することは、売上の機会損失とSEO評価の失墜に直結します。本記事の知識を活用し、パフォーマンスのボトルネックを根本から排除してください。
あわせて読みたい(関連記事)
504エラーとセットで発生・混同されやすいその他の重要ステータスコードや、インフラ・開発設計に関する専門ガイドも併せてご活用ください。
▶︎ 502 Bad Gatewayの解決ガイド – プロセス枯渇とソケットのチューニング
▶︎ 400 Bad Requestの原因と対処 – JWT肥大化とREST APIパースエラー



